When using framework mode, React Router allows you to export a handleError function in your server entry point, entry.server.tsx . If you don't see this file, you can run npx react-router reveal to have one created(a default is provided behind the scenes).
If you look at the docs you can see how to implement a handleError function.
// entry.server.tsx
import { type HandleErrorFunction } from "react-router";
// ...
export const handleError: HandleErrorFunction = (
error,
{ request }
) => {
// React Router may abort some interrupted requests, don't log those
if (!request.signal.aborted) {
myReportError(error);
// make sure to still log the error so you can see it
console.error(error);
}
};
The docs end there, leaving it up to you to figure out what the myReportError function should look like though.
Sentry is a popular application monitoring platform that you can be used here but maybe you don't want to rely on a 3rd party service for this or maybe your company has strict limitations that don't allow for this. There's several reasons why Sentry(or another platform) can't be used but heck, we should be able to figure something out, right? Error reporting is kind of important. I want to know about any errors getting thrown in my apps.
Disclaimer
What we're going to build is obviously not as fully featured as what various monitoring platforms provide. I'm also intentionally going to prioritize straightforwardness over optimization for clarity's sake. My goal is to equip you with a concept to further iterate on and adapt to your specific needs. This is also strictly for errors that occur on the server, not in the browser. That'll have to be another post.
Alright, let's go.
Setup
We're going to be using the completed React Router tutorial like I have in my previous posts. You can grab that here if you'd like to follow along.
Wrecking havoc
Let's start with intentionally introducing some code that will throw an error:
// app/routes/contact.tsx
export async function loader({ params }: Route.LoaderArgs) {
const contact = await getContact(params.contactId);
if (!contact) {
throw new Response("Not Found", { status: 404 });
}
params.read(); // <- there is no `read` method on params!
return { contact };
}
If we start the app in dev mode(npm run dev) and go to this route we'll see this:
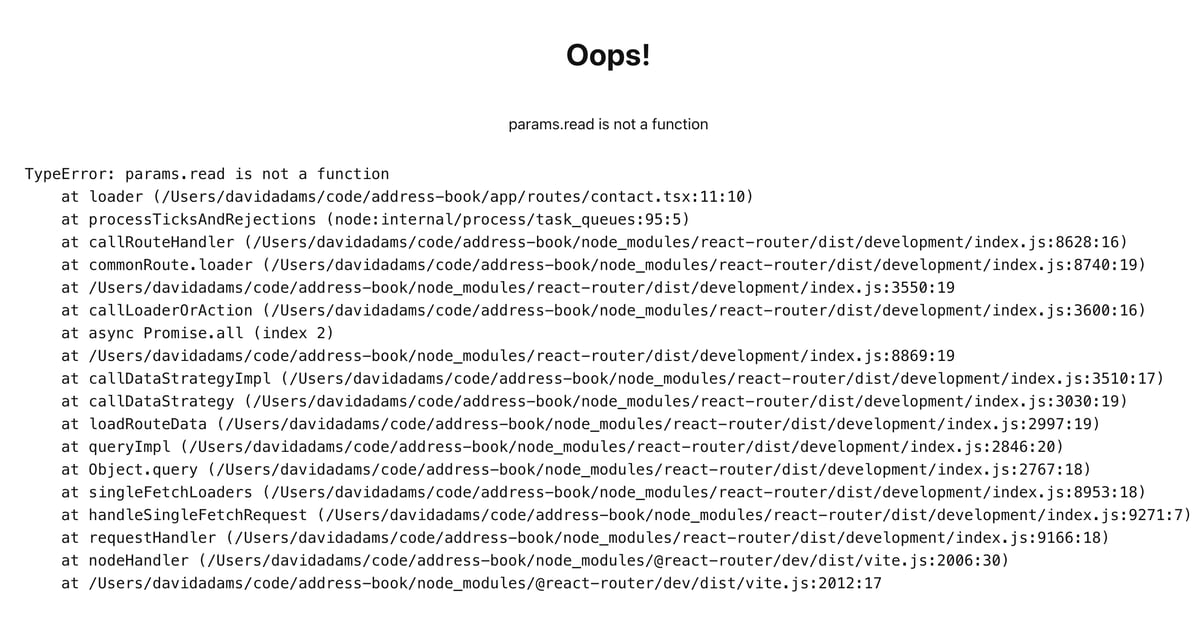
This is pretty nice or React Router to provide for us out of the box. We can see the code that's causing the error as well as the file, line number, and character on that line: app/routes/contact.tsx:11:10. This same error is logged in the console too.
There's a problem though. This is development. What does this look like after the app has been build for production? Let's try that with npm run build && npm start and visiting the page. Now we get a less helpful error page in the browser but that's a good thing. We don't want to expose that stuff to our users.
However, now the error logged in the console is a lot less useful.
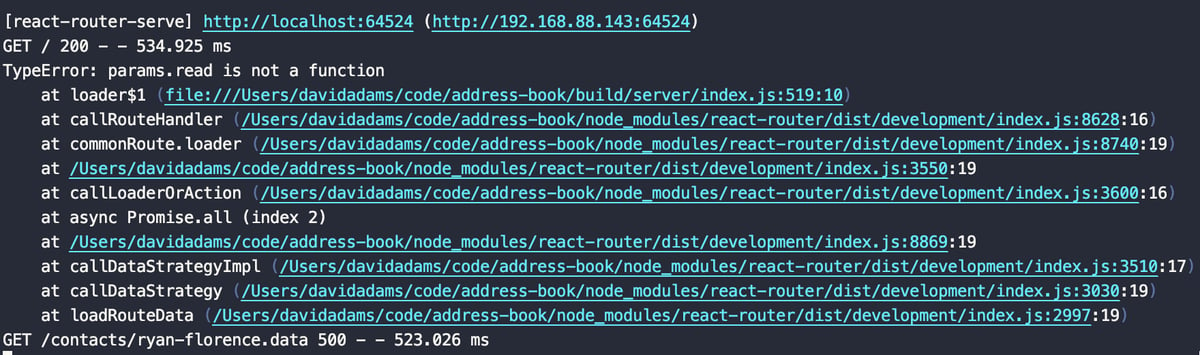
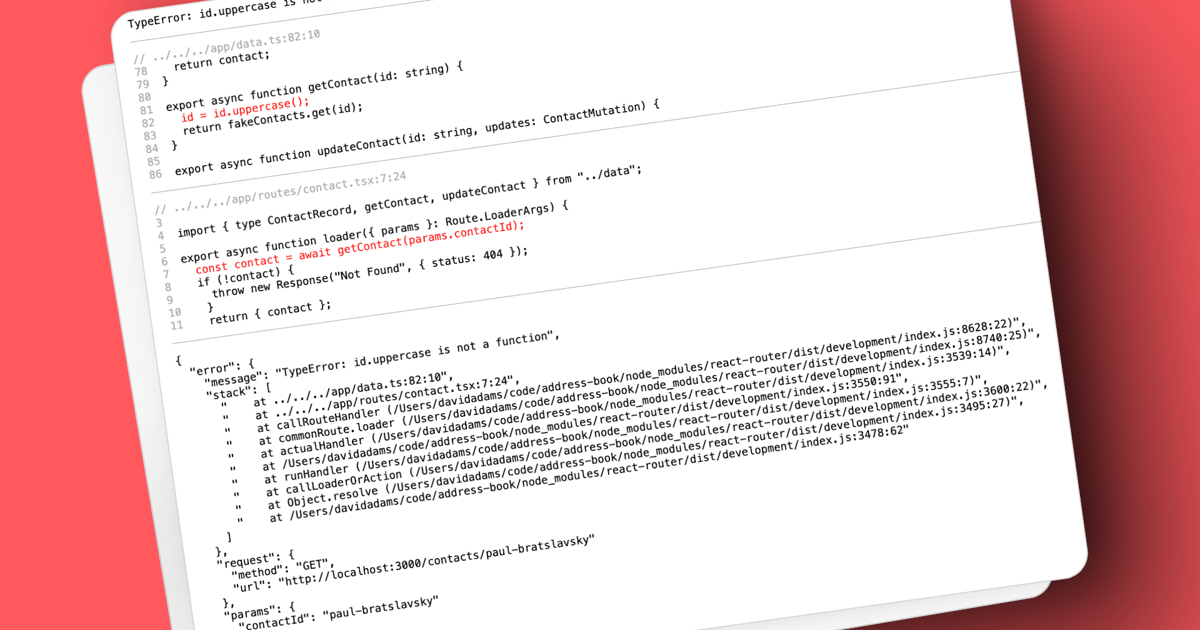
We can still see the params.read is not a function error message but now the error is originating from build/server/index.js:519:10. If we look at the built code we can see where it's coming from on line 519.
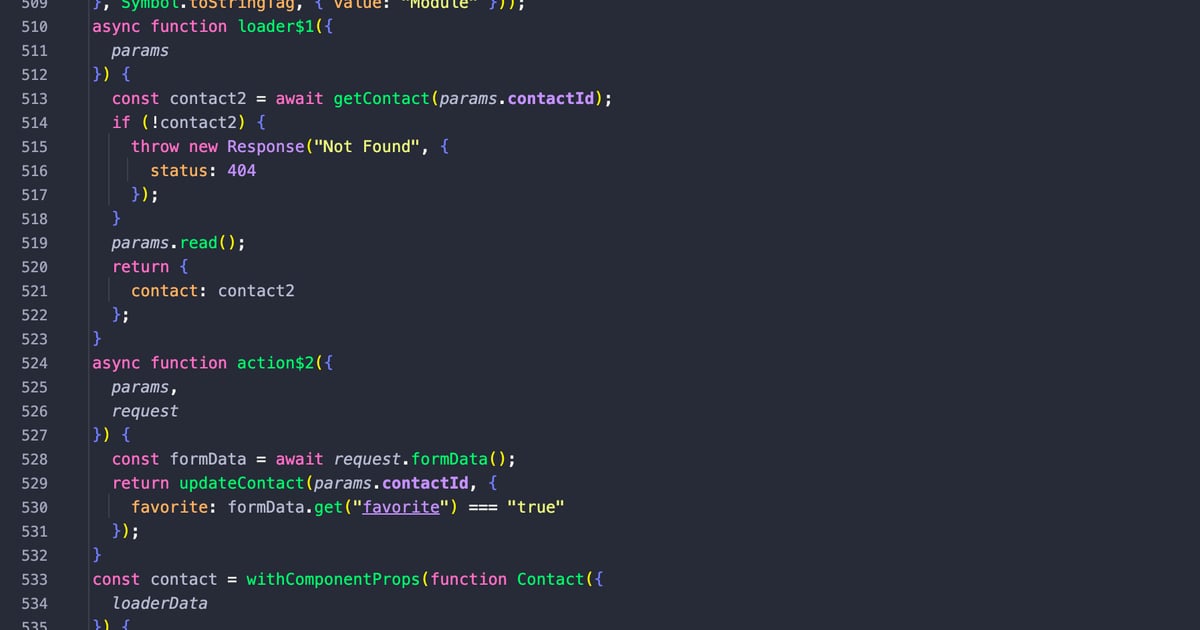
The server code has all been bundled up into this single file though. We don't have a good way to know where exactly this is in our source code. That's a pretty critical piece of information we just don't have.
Source maps to the rescue
This problem is exactly what source maps are for. These generated files help map built code to source code. You have to explicitly tell vite to generate them in your vite.config.ts file.
import { reactRouter } from "@react-router/dev/vite";
import { defineConfig } from "vite";
export default defineConfig({
build: {
sourcemap: true,
},
plugins: [reactRouter()],
});
Now when we build, npm run build, we get a warning message.
⚠️ Source maps are enabled in production
This makes your server code publicly
visible in the browser. This is highly
discouraged! If you insist, ensure that
you are using environment variables for
secrets and not hard-coding them in
your source code.
This is important but we'll come back to in a bit. Aside from the warning message, we also get <filename>.js.map files generated for every built js file. These are the source maps.
These files consist of json. If you copy/paste the contents of the build/server/index.js.map and paste it into a browser console, you can more easily see the structure and what exactly is inside.

It contains function names, sources files, the actual source code in sourcesContent, and the wizardry that correlates the built code to the source code in the mappings.
When we turned source maps on, it means we're generating source maps for both the server code and the client code. This means that your client source code would be fully exposed. If you prefer that to not happen we can take care of that by modifying our package.json.
"scripts": {
"build": "cross-env NODE_ENV=production react-router build && npm run rm-client-source-maps",
"dev": "react-router dev",
"start": "cross-env NODE_ENV=production react-router-serve ./build/server/index.js",
"typecheck": "react-router typegen && tsc",
"rm-client-source-maps": "find build/client -type f -name '*.map' -delete"
},
We've modified the build script to also run a new rm-client-source-maps script that will do exactly as the name implies. Now our client source code won't be exposed for all to see.
source-map-support
The default React Router npm start script uses the @react-router/serve package which uses express behind the scenes. You can see what exactly this is doing here. Notice that the first thing it does is setting up source map support. If you've ejected from the default and using your own express implementation, be sure to add this same setup by installing the source-map-support package and bringing that snippet over.
With this in place, your stack traces will look more like how they do doing development where the files and lines reference your source code. 🎉
Implementing handleError
Now, let's take a stab at writing a handleError implementation.
import nodemailer from "nodemailer";
import type { SendMailOptions } from "nodemailer";
// ...
export const handleError: HandleErrorFunction = (error, args) => {
const { request, context, params } = args;
// React Router may abort some interrupted requests, don't log those
if (request.signal.aborted) return;
let message = "Unknown Error.";
let stack: Array<string> = [];
if (error instanceof Error) {
const lines = error.stack?.split("\n") ?? [];
message = lines[0]; // Error message line
stack = lines.slice(1); // Actual stack lines
}
// build up an object with all of the relevant details
const payload = {
error: {
message,
stack,
},
request: {
method: request.method,
url: request.url,
},
params,
context: {
// values from context, maybe?
},
env: {
// values from process.env, maybe?
}
};
sendMail({
from: process.env.MAILER_SEND_ERRORS_FROM,
to: process.env.MAILER_SEND_ERRORS_TO,
subject: 'MyApp - ERROR',
html: `<pre><code>${JSON.stringify(payload, null, 2)}</pre></code>`,
}).catch(console.error)
// make sure to still log the error so you can see it
console.error(error);
};
function sendMail(options: SendMailOptions) {
const transporter = nodemailer.createTransport({
host: process.env.MAILER_HOST ?? "",
port: Number(process.env.MAILER_PORT),
secure: process.env.MAILER_SECURE === "true",
ignoreTLS: process.env.MAILER_IGNORE_TLS === "true",
auth: {
user: process.env.MAILER_USER ?? "",
pass: process.env.MAILER_PASSWORD ?? "",
},
});
return transporter.sendMail(options);
}
This assumes you have all those process.env.[field] values defined and configured correctly but we're just sending an email with JSON containing all the important bits about what happened. You could totally pretty this up in the html instead of sending raw JSON but you get the idea. Instead of sending an email, you could post to slack, telegram, api endpoint, etc. Whatever works for your situation.
This a huge step up from not having any sort of error reporting.
Can we do better?
The main problem with this is the fact that we only have the source code file and line number. You'd need to have the same code that was built in front of you to look at the surrounding lines to really get the context around this error. It'd be pretty nice if we could get that in the message we're sending out...
Custom server
To do what we're after we need to not use the default server so we can opt out of the source map setup. This is definitely counterintuitive but the issue is that if we keep the current source map setup we only have the stack entries with the source code file names and line numbers. If we deploy our app with the source code we could easily get the source code lines around the stack entries. However, you typically don't ship your source code to prod, only the built assets.
Think of it this way... If the following line is what we have access to in the handleError function
at loader$1 (file:///Users/davidadams/code/address-book/app/routes/contact.tsx:11:10
but we don't have the corresponding source code to inspect where this is running, well then that's as much information as we can get.
What we need is the originally unhelpful version.
at loader$1 (file:///Users/davidadams/code/address-book/build/server/index.js:541:10)
We can manually combine this information with the source map(that will get deployed where this is running) to not only get the source code line that the error originated from but also the lines around it.
Using the node-custom-server example
Luckily, React Router has an example that we can use to implement a custom server(which is still express). Find that here. There are a number of changes we need to make.
npm install compression morgan express @type/express- Copy the server.js to the root of our project.
- Copy the server/app.ts file into our project.
- Update our
vite.config.ts to reference the server/app.ts file
import { reactRouter } from "@react-router/dev/vite";
import { defineConfig } from "vite";
export default defineConfig(({ isSsrBuild }) => ({
build: {
sourcemap: true,
rollupOptions: isSsrBuild
? {
input: "./server/app.ts",
}
: undefined,
},
plugins: [reactRouter()],
}));
- Finally, update our
package.json scripts.
"scripts": {
"build": "cross-env NODE_ENV=production react-router build && npm run rm-client-source-maps",
"dev": "cross-env NODE_ENV=development node server.js",
"start": "node server.js",
"typecheck": "react-router typegen && tsc",
"rm-client-source-maps": "find build/client -type f -name '*.map' -delete"
},
With any luck, you'll be able to npm run dev , npm run build, and npm start like you normally would and it will all work the same.
Now we're generating source maps and not having the source-map-support do its install to fix our stack traces to reference our source code. We have our blank canvas.
Manually using source maps
To make use of source maps ourselves we need to install the source-map package.
npm install source-map
We can use the SourceMapConsumer class to get back to where we were:
// ...
import fs from "node:fs";
import { SourceMapConsumer } from "source-map";
export const handleError: HandleErrorFunction = async (error, args) => {
const { request, context, params } = args;
// React Router may abort some interrupted requests, don't log those
if (request.signal.aborted) return;
let message = "Unknown Error.";
const processedStack: Array<string> = [];
if (error instanceof Error) {
const lines = error.stack?.split("\n") ?? [];
message = lines[0]; // Error message line
const stack = lines.slice(1); // Actual stack lines
for (const line of stack) {
// parse the file path, line number, and column number from the line
const match = line.match(/at .+ \((.+):(\d+):(\d+)\)/);
if (!match) {
processedStack.push(line);
continue;
}
const [_, filePath, lineNum, colNum] = match;
// only process our own built files, not vendor files
if (!filePath.includes("/build/server/")) {
processedStack.push(line);
continue;
}
// get the source map contents
const sourceMapFile = `${filePath}.map`.replace("file:", "");
const sourceMap = fs.readFileSync(sourceMapFile).toString();
// use the source map
await SourceMapConsumer.with(sourceMap, null, async (consumer) => {
// get the source code position
const position = consumer.originalPositionFor({
line: parseInt(lineNum),
column: parseInt(colNum),
});
// if the source cannot be found, add the original line
if (!position.source) {
processedStack.push(line);
return;
}
// we found the source. Use it!
processedStack.push(
` at ${position.source}:${position.line}:${position.column}`,
);
});
}
}
const payload = {
error: {
message,
stack: processedStack,
},
// ...
};
// ...
};
The above code builds up a processedStack which are the stack lines where lines to our built code get translated to their source code counterparts. If we JSON stringified the payload and logged it this is what we get:
{
"error": {
"message": "TypeError: params.read is not a function",
"stack": [
" at ../../../app/routes/contact.tsx:11:9",
" at async callRouteHandler (/Users/davidadams/code/address-book/node_modules/react-router/dist/development/index.js:8628:16)",
// ...
]
},
// ...
}
Notice the first item in the stack array. It contains a reference to our source code. Perfect.
Now we can focus on getting the source at that line and a number of lines around it so we can immediately get a better sense of where this code is and what it's doing.
The goal
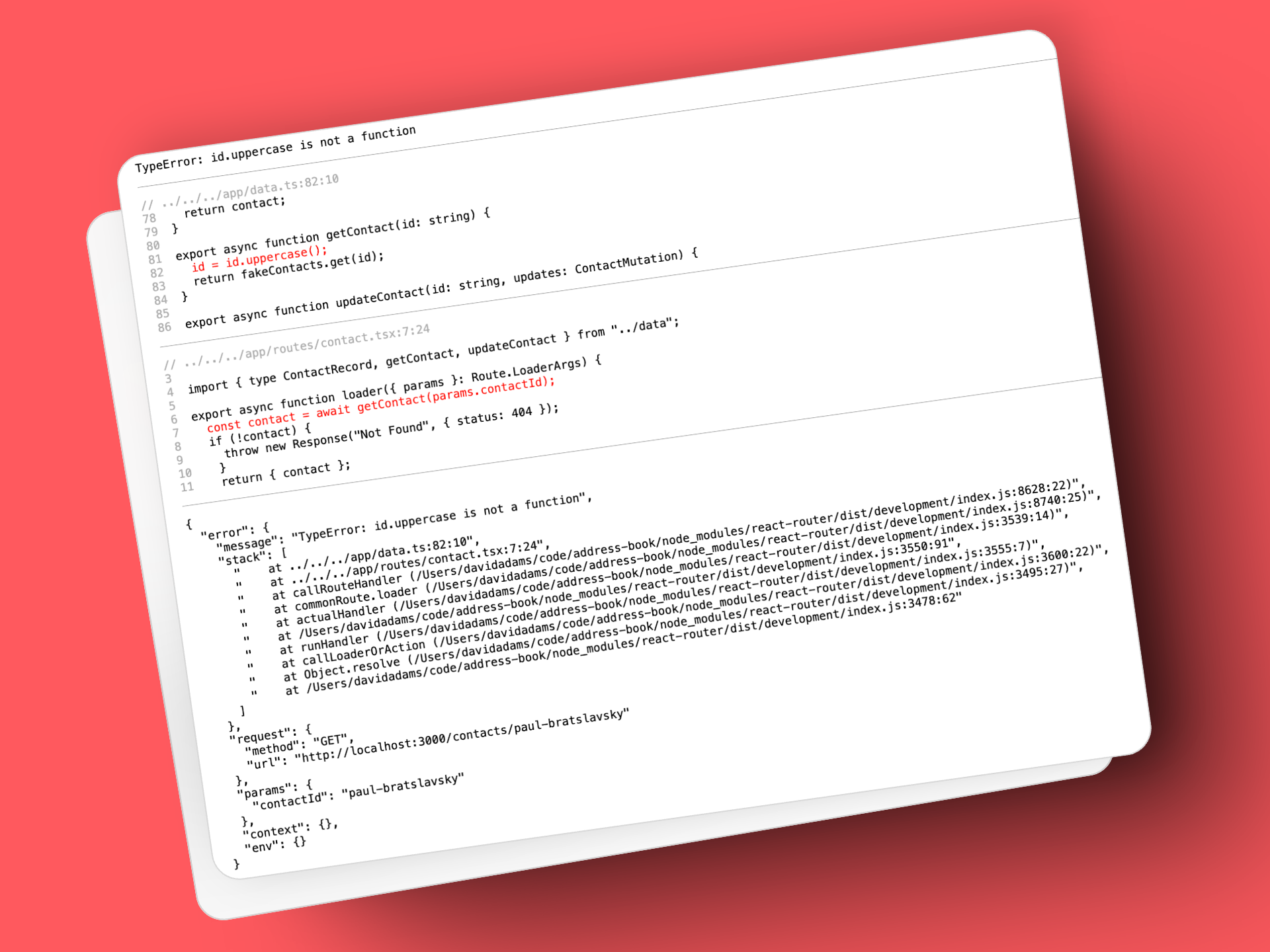
In our scenario, there's only a single line to our source code. However, there could be several lines that reference your source code if an error is thrown deep in multiple function calls. For example, say we had an error here instead of our directly in our loader:
// app/data.ts
export async function getContact(id: string) {
id = id.uppercase(); // <- it's .toUpperCase(), not .uppercase()!
return fakeContacts.get(id);
}
Our payload would look like this:
{
"error": {
"message": "TypeError: id.uppercase is not a function",
"stack": [
" at ../../../app/data.ts:82:10",
" at ../../../app/routes/contact.tsx:7:24",
// ...
]
},
There's a trail of lines in our source code. It would be super helpful if we could get the source code around those lines. Let's come up with a typescript type to design what we want.
type AppStackLine = {
filename: string; // ../../../app/data.ts
lineNumber: number; // 82
columnNumber: number; // 10
sourceCodeContext: Array<{
lineNumber: number;
code: string;
}>;
};
For every entry in the stack that references our source code, we want the details of where the stack trace line is in the source code but also the source code lines itself. Each line will be represented by an object with the source code line number and the code itself.
We can write a function that when given a source map position, will provide us with an AppStackLine that contains the source code around that position. This function takes a linesAround property to make it easy to adjust just how much source code we want to see.
// entry.server.ts
// ...
function getAppStackLine({
consumer,
position,
linesAround,
}: {
consumer: SourceMapConsumer;
position: NullableMappedPosition;
linesAround: number;
}) {
if (!position.source || !position.line || !position.column) return null;
// get the source code
const sourceCode = consumer.sourceContentFor(position.source);
if (!sourceCode) return null;
// create an AppStackLine
const appStackLine: AppStackLine = {
filename: position.source,
lineNumber: position.line,
columnNumber: position.column,
sourceCodeContext: [],
};
// split the source code file into an array of lines
const lines = sourceCode.split("\n");
// get the index of the line that showed up in the stack trace
const targetLineIndex = position.line - 1;
// calculate the range of lines to include
const startLine = Math.max(0, targetLineIndex - linesAround);
const endLine = Math.min(lines.length - 1, targetLineIndex + linesAround);
// get the source code lines
for (let i = startLine; i <= endLine; i++) {
appStackLine.sourceCodeContext.push({
lineNumber: i + 1,
code: lines[i],
});
}
return appStackLine;
}
Let's incorporate that into our handleError function.
// entry.server.ts
// ...
import { type NullableMappedPosition, SourceMapConsumer } from "source-map";
export const handleError: HandleErrorFunction = async (error, args) => {
const { request, context, params } = args;
// React Router may abort some interrupted requests, don't log those
if (request.signal.aborted) return;
let message = "Unknown Error.";
const processedStack: Array<string> = [];
const appStackLines: Array<AppStackLine> = [];
if (error instanceof Error) {
const lines = error.stack?.split("\n") ?? [];
message = lines[0]; // Error message line
const stack = lines.slice(1); // Actual stack lines
for (const line of stack) {
// parse the file path, line number, and column number from the line
const match = line.match(/at .+ \((.+):(\d+):(\d+)\)/);
if (!match) {
processedStack.push(line);
continue;
}
const [_, filePath, lineNum, colNum] = match;
// only process our own built files, not vendor files
if (!filePath.includes("/build/server/")) {
processedStack.push(line);
continue;
}
// get the source map contents
const sourceMapFile = `${filePath}.map`.replace("file:", "");
const sourceMap = fs.readFileSync(sourceMapFile).toString();
// use the source map
await SourceMapConsumer.with(sourceMap, null, async (consumer) => {
// get the source code position
const position = consumer.originalPositionFor({
line: parseInt(lineNum),
column: parseInt(colNum),
});
// if the source cannot be found, add the original line
if (!position.source) {
processedStack.push(line);
return;
}
processedStack.push(
` at ${position.source}:${position.line}:${position.column}`,
);
const appStackLine = getAppStackLine({
consumer,
position,
linesAround: 4,
});
if (appStackLine) {
appStackLines.push(appStackLine);
}
});
}
}
// ...
};
Now if we log the JSON stringified appStackLines we can see the relevant source code.
[
{
"filename": "../../../app/data.ts",
"lineNumber": 82,
"columnNumber": 10,
"sourceCodeContext": [
{
"lineNumber": 78,
"code": " return contact;"
},
{
"lineNumber": 79,
"code": "}"
},
{
"lineNumber": 80,
"code": ""
},
{
"lineNumber": 81,
"code": "export async function getContact(id: string) {"
},
{
"lineNumber": 82,
"code": " id = id.uppercase();"
},
{
"lineNumber": 83,
"code": " return fakeContacts.get(id);"
},
{
"lineNumber": 84,
"code": "}"
},
{
"lineNumber": 85,
"code": ""
},
{
"lineNumber": 86,
"code": "export async function updateContact(id: string, updates: ContactMutation) {"
}
]
},
{
"filename": "../../../app/routes/contact.tsx",
"lineNumber": 7,
"columnNumber": 24,
"sourceCodeContext": [
{
"lineNumber": 3,
"code": ""
},
{
"lineNumber": 4,
"code": "import { type ContactRecord, getContact, updateContact } from \"../data\";"
},
{
"lineNumber": 5,
"code": ""
},
{
"lineNumber": 6,
"code": "export async function loader({ params }: Route.LoaderArgs) {"
},
{
"lineNumber": 7,
"code": " const contact = await getContact(params.contactId);"
},
{
"lineNumber": 8,
"code": " if (!contact) {"
},
{
"lineNumber": 9,
"code": " throw new Response(\"Not Found\", { status: 404 });"
},
{
"lineNumber": 10,
"code": " }"
},
{
"lineNumber": 11,
"code": " return { contact };"
}
]
}
]
All that's left to do is put into an email(or slack, telegram, etc). Here's a very crude html email we can throw together with the payload and appStackLines we've built up.
// entry.server.tsx
// ...
// start building up html snippets. the first being the error message
const snippets = [`<pre><code>${payload.error.message}</code></pre>`];
const commentColor = "#ababab";
// for every app stack line...
for (const appStackLine of appStackLines) {
// create a code block
let snippet = `<pre><code>`;
// that starts with the file:lineNumber:columnNumber
snippet += `<span style="color: ${commentColor};">// ${appStackLine.filename}:${appStackLine.lineNumber}:${appStackLine.columnNumber}</span>\n`;
// then, for every source code line...
for (const line of appStackLine.sourceCodeContext) {
// determine if we should highlight it based on the line
// number matching the stack trace line number
const color =
line.lineNumber === appStackLine.lineNumber ? "red" : "black";
// append the source code line itself
const lineNumberSpan = `<span style="color: ${commentColor};">${line.lineNumber}</span>`;
snippet += `<span style="color: ${color};">${lineNumberSpan} ${line.code}</span>\n`;
}
snippet += `</pre></code>`;
snippets.push(snippet);
}
// include the payload object we put together earlier
snippets.push(`<pre><code>${JSON.stringify(payload, null, 2)}</code></pre>`);
sendMail({
from: process.env.MAILER_SEND_ERRORS_FROM,
to: process.env.MAILER_SEND_ERRORS_TO,
subject: "App - ERROR",
html: snippets.join("<hr />"),
}).catch(console.error);
// ...
Bonus: set up a dummy smtp server
If you're not afraid of docker, run this to spin up a local dummy smtp server that will catch every outgoing email instead them actually being sent to their recipients.
docker run --rm -it -p 5000:80 -p 2525:25 rnwood/smtp4dev
Run npm install dotenv and then add the following line to your server/app.ts file.
// server/app.ts
// ...
import "dotenv/config";
// ...
Then create a .env file in the root the project with the following contents. Don't forget to add this to your .gitignore file.
MAILER_SEND_ERRORS_FROM="[email protected]"
MAILER_SEND_ERRORS_TO="[email protected]"
MAILER_HOST="localhost"
MAILER_PORT=2525
MAILER_USER="user"
MAILER_PASSWORD="password"
MAILER_SECURE="false"
MAILER_IGNORE_TLS="true"
This will spin up an inbox at http://localhost:5000 you can go to to see all caught emails. Super handy for local development when emails are involved.
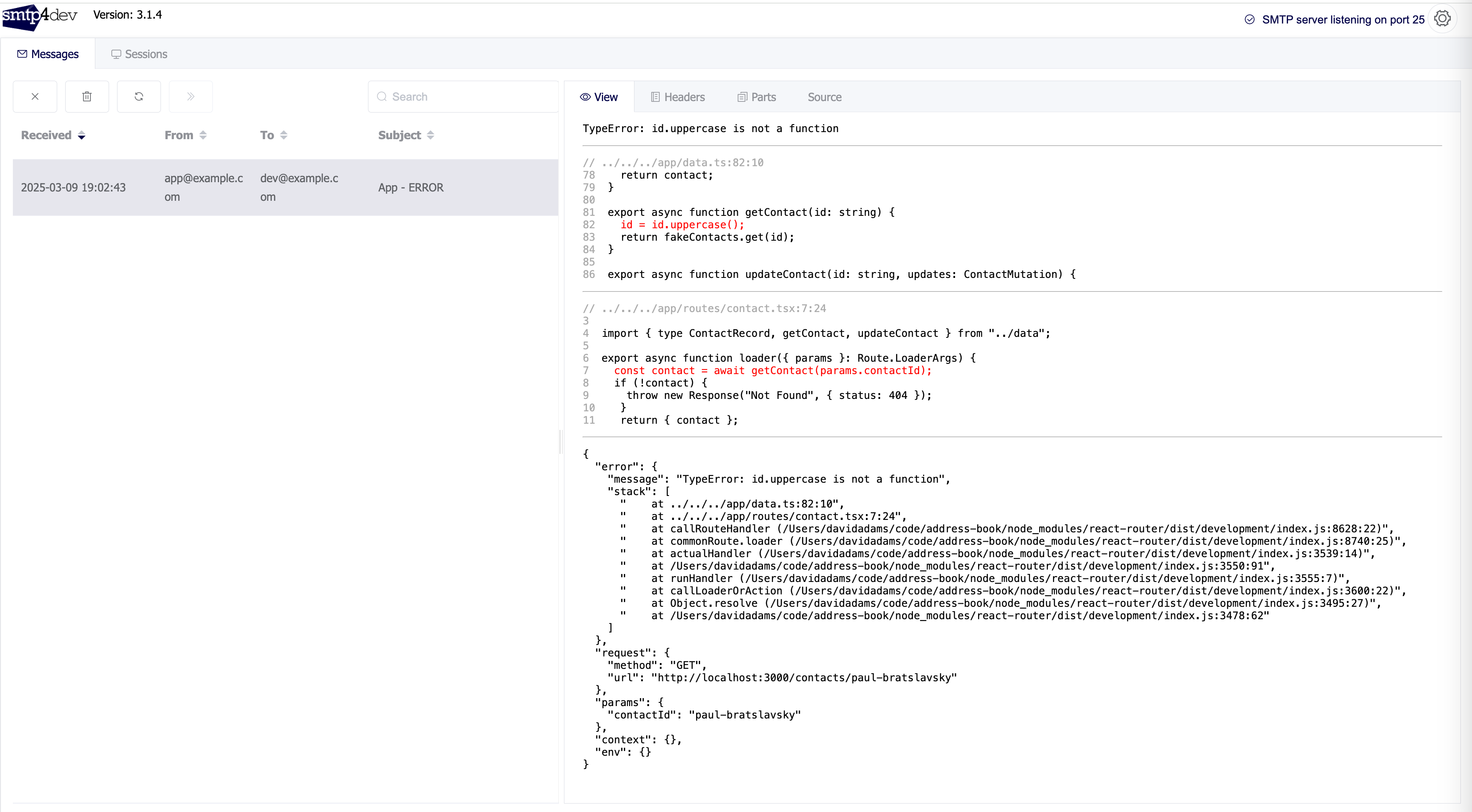
Now if you npm run build and npm start the "production" app and go to the route that triggers the error you'll get sent this email.
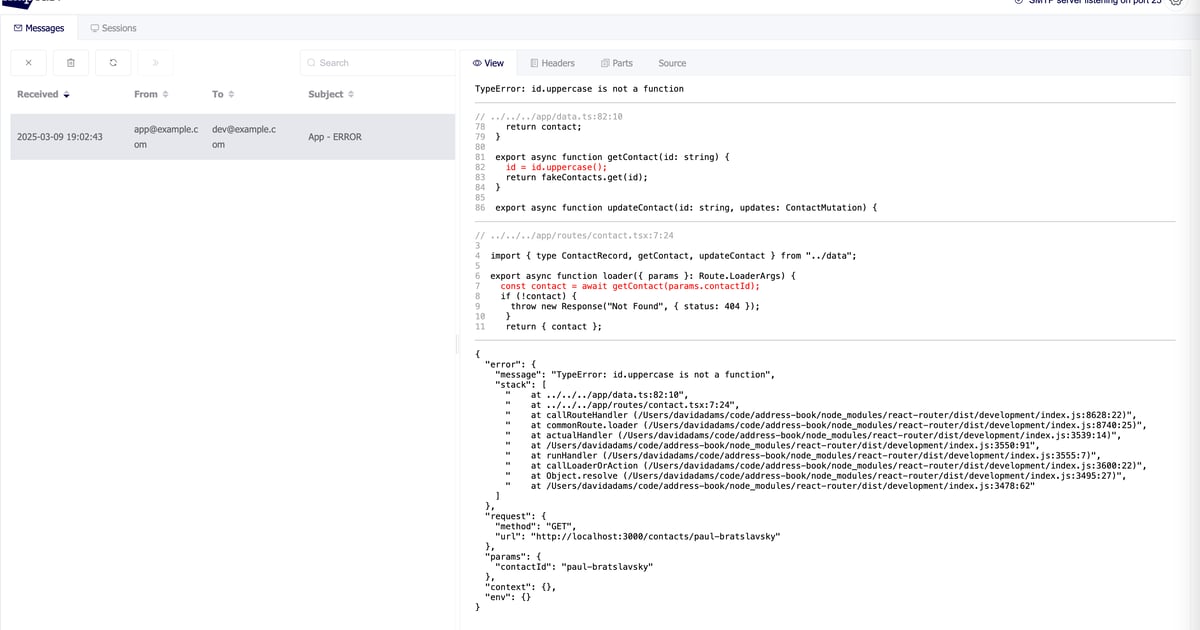
We've got our actual code and the lines that are in the stack trace in red. We're now instantly able to tell where errors are coming from. 🎉
Disclaimer again
This code is not optimized. Every line in our stack trace that comes from our source code is rereading in the source map file and reinitializing a new source map consumer. I'll leave optimization up to you and Claude. 🤖
I can't use fs, halp!
Some platforms, like Cloudflare's workers don't provide fs support so you wouldn't be able to read the contents of the source map file.
What you can do instead is make uploading the source maps to somewhere your app can retrieve part of your deployment process. For example, you could upload them to a bucket in R2/S3 and retrieve them from their instead of the filesystem.
Standalone error reporting app
You could also go as far as standing up a dedicated error reporting app(like Sentry) where instead of doing all this processing directly in handleError, you could POST the error message and stack trace to this separate app where all the logic we've implemented here would live. This would be ideal if you're running a lot of apps but prefer not either implement the same thing over and over again or don't want your apps to be burdened with handling this.
Fix bugs faster
I hope you've learned something and you see that what we've covered can be applied elsewhere and isn't too React Router specific. Go forth, create an ErrorBoundary that says you've been notified about the error and actually mean it now. 👍
You can find the full source code here. If you want to run it, just be sure to copy the example.env to .env in the root of the project.
Let me know if you've learned something on X at @dadamssg. Would love to know if this was helpful.
Also be sure to sign up below to be notified of any new stuff I publish. ✌️